Teaching Old Workers New Tricks
By Alex Streed •
Workers are a very important part of Prefect. They handle spinning up infrastructure for scheduled flow runs, tracking that infrastructure to ensure nothing goes wrong during execution, and reporting back to the orchestration server if something does go wrong. For most of their life, workers have had a dirty little secret: they aren’t very good at the last part. Sure, if they lived in a magical land where instances never crash and the network is always fully reliable with APIs that are 100% available, then they’d be crushing it. The problem is that we live in reality, and all sorts of problems happen on a regular basis.
In the happy path, the worker spins up infrastructure like a Kubernetes Job or an ECS task, does some busy watching, and then doesn’t have to do anything else because the process running in the infrastructure exits successfully. In Prefect, our execution engine is responsible for reporting failures and some types of crashes. For some scenarios that the engine can’t handle, we have a watcher process that keeps an eye on the flow run to report cancellations and more types of crashes without the worker getting involved. The worker only gets involved when some crash happens that prevents the watcher process from reporting a final state before it disappears. This is really like a line of Hawtch-Hawtchers watching a bee.
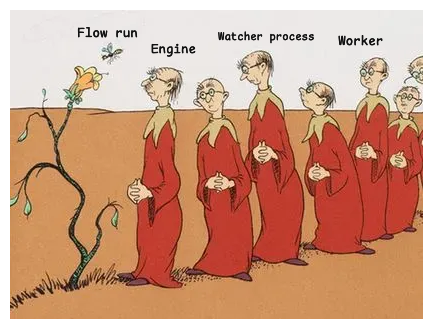
It’s Hawtch-Hawtchers all the way down
This all goes terribly awry when the worker instance goes down after submitting a flow run to infrastructure. You see, workers hold in memory the flow runs that they’ve submitted so that they can check up on them periodically. When a worker goes down, that state is completely lost.
In the happy path, this is fine because the engine and watcher process can handle most outcomes. But if flow run infrastructure vanishes due to a pod eviction or VM crash, there’s no one there to see that the beacons have been lit and ride to Gondor’s aid1. And now you have zombie flow runs cluttering up your system.
This scenario (where a worker can’t report crashes) becomes common at scale. Pod evictions in a large Kubernetes cluster are commonplace, and we weren’t handling it well at all. After an eye-opening discussion with a user that was struggling with zombie runs, it became clear that a new architecture was needed. We’d been assuming workers were durable enough to hold run state in memory, but that assumption was painfully wrong.
So we decided to split our Kubernetes worker into two parts: submission and observation. We needed the state for runs to live somewhere more durable so that worker instances could come and go without affecting our ability to report crashes. Turns out, Kubernetes is a pretty darn durable state store that’s happy to tell us what’s happening in real time, and there are libraries that make it easy to hook into that. We decided to incorporate kopf into our Kubernetes worker to act as our observation layer, and it worked wonderfully. Now, instead of polling job status every couple of seconds, we respond to pod and job events emitted by Kubernetes. Since Kubernetes manages those events, any worker can receive and respond to them, and there’s enough metadata in the events that the worker no longer needs to hold long-term state. Since the PR to introduce this new architecture has been merged and released, nearly all of the issues that we had with the Kubernetes worker have disappeared, and (most importantly) users are happy.
That’s one good story, but we have workers for lots of infrastructure types that still have issues. So now we’re in the process of updating all our workers to use an event-based architecture so that they’ll work just as well as our Kubernetes worker does today. I’m working on the ECS worker right now and, unfortunately, I haven’t been able to find a kopf equivalent for ECS, so I’m doing my best kopf impersonation with EventBridge and SQS. When all is said and done, the new architecture will look something like this:

All in all, this has been a good reminder that we live in the real world, things go wrong all the time, and, when possible, you should make managing state someone else’s problem. 😉
A Dr. Seuss and a LOTR reference? You’re all over the place today bud. ↩︎